
Nedávno, při návštěvě jedné společnosti pracující v oblasti internetu věcí, jsem se dostal do diskuse s jedním z jejích technických vedoucích. Mluvili jsme o rozdílu mezi M2M (komunikace machine-to-machine, tedy mezi stroji) a IoT (internetem věcí). Jeho názor byl, že oni dělají v podstatě totéž. Podle jeho názoru internet věcí pouze přidává nové senzory pro sběr dat v nižších cenových kategoriích a silnější výpočetní kapacity v podniku k umožnění mohutného shromažďování dat a analýzy. Shrnul to tím, že řekl něco ve smyslu: „Měříme data novými čidly, předáváme je podniku, kde s nimi nějací šikovní lidé dělají chytré věci a transformují je do akceschopných informací.“
Zcela tak pominul některé základní rozdíly mezi „starým“ M2M a „novou“ architekturou internetu věcí. Zejména, jak se zdá, zcela přehlédl způsoby, jakými internet věcí předzpracovává data na vstupu do sítě před jejich odesláním k upotřebení, a věci, co internet věcí dělá, když data přenáší do podniku.
Tradiční M2M systémy byly typicky aplikovány k monitorování, kontrole nebo optimalizaci jediného procesu. Byly specifikovány, navrženy a zavedeny k okamžitému řešení problému okamžitým řešením. Příkladem použití staré M2M architektury by mohla být budova s oddělenými systémy pro řízení klimatizace, bezpečnosti a detekci požáru. Docela často tyto diskrétní systémy přijímají stejná měření ze stejných míst od samostatných snímačů. Snímače jsou zapojeny zpět do oddělených přístrojových skříní, a vyvedeny na oddělené obrazovky obsluhy. Každý systém tak komunikuje interně s využitím vlastních (často proprietárních) protokolů a standardů. Sdílení dat mezi takovými systémy je obtížné, často nemožné.
M2M
Jedná se o machine to machine řešení, které umožňuje bezdrátově i kabelem připojeným zařízením komunikovat s ostatními zařízeními, které mají stejné možnosti. To vše bez nutnosti jakéhokoliv lidského zásahu. M2M zařízení zaznamenávají konkrétní události (teplotu, stav zásob, atd.) a ukládají je do PC programu, který tyto záznamy převádí do smysluplných hodnot.
Jedná se o machine to machine řešení, které umožňuje bezdrátově i kabelem připojeným zařízením komunikovat s ostatními zařízeními, které mají stejné možnosti. To vše bez nutnosti jakéhokoliv lidského zásahu. M2M zařízení zaznamenávají konkrétní události (teplotu, stav zásob, atd.) a ukládají je do PC programu, který tyto záznamy převádí do smysluplných hodnot.
Na druhou stranu je M2M systémy poměrně snadné určit. Když máme co do činění s problémem okamžitého zpracování, můžeme rozšířit měření, které musíme udělat, a způsob, jakým chceme získané informace shrnout. Mohou být definovány hranice toho, čeho chceme dosáhnout, a je poměrně jednoduché ospravedlnit (nebo odmítnout) otázku návratu investic.
Tradiční M2M systém může být znázorněn jako manažer sedící v kanceláři, neustále napojený na svůj tým vzdálených pracovníků v nikdy nekončícím cyklu. Manažer se ptá, jestli je vše v pořádku, a zabývá se každou událostí, která se objeví. K tomu musí manažer vědět, jak kontaktovat a jak si vyměňovat informace s každým ze svých zaměstnanců. A protože povaha šetření se opakuje a téma diskuse je omezené, všichni používají „zkratkový“ jazyk, kterému vzájemně rozumějí. To jim umožňuje mezi sebou komunikovat docela efektivně. Ale jejich jazyk není jednoduše srozumitelný v ostatním světě, a nemohou se snadno přizpůsobit novým situacím a případům použití.
Na druhé straně u internetu věcí jde o systémy systémů. Jde o to, že producenti dat zveřejňují informace, aniž by museli vědět, jaké aplikace nebo jací uživatelé budou tato data zpracovávat. Taková data jsou k dispozici více systémům tak, že mohou být rozšířena a revidována v okamžiku, kdy se nové požadavky objeví. Musíme tedy být schopni zkoumat závislosti a příčinné souvislosti mezi zdánlivě nesouvisejícími datovými kanály. Optimalizovat tedy nelze jen jeden proces, ale celý ekosystém, při ziskání schopnosti přizpůsobovat a vyvíjet nové požadavky a používat výchozí případy. Je to o měnícím se využíváním stávajících dat a jejich volném kombinování, aniž by bylo třeba definovat vše, co chcete dělat, v první den projektu. Počáteční případ užití může odůvodnit náklady na pořízení systému, ale nemusíme nutně vědět, jak budeme chtít systém rozšiřovat. Architektury IoT musí poskytnout tuto flexibilitu, která nikdy nebyla nejdůležitějším aspektem v tradičním M2M.
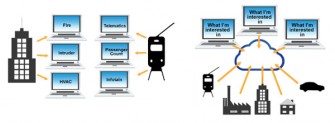
Mohli bychom to brát jako „Twitter pro stroje“. Jsem-li zařízení, vše co musím udělat je přihlásit se k tématu zájmu. Nepotřebuji vědět, kdo jsou tweetující, nebo jak jsou připojeni k síti. Jednoduše dostávám odpovídající informace, a já pak mohu určit, co ignorovat, a co se zpracovat. Jiná zařízení, která mají zájem o stejné téma z jejich vlastních důvodů, se mohou také rozhodnout, že je budou sledovat. Stejně jako já obdrží tyto informace, aniž by musely provádět nějaké změny u producentů informací. A mohou to udělat bez vlivu na mě a na to, co dělám. Nová zařízení se mohou kdykoliv k datům přihlásit a stávající zařízení se mohou kdykoliv odhlásit. Žádné z těchto zařízení se navzájem neruší. Stejně tak se mohou kdykoliv on-line připojit další producenti informací a začít posílat své příspěvky do fondu informacemí.
Mnohá data jsou samozřejmě kriticky důležitá. A ve světě internetu věcí jsou informace přenášeny bez lidského zásahu. Naše bezpečnostní a zotavovací procedury musí být velmi robustní. Potřebujeme také definice témat, která mají jemnější zrnitost než jednoduchý hashtag (klíčové slovo).
Vraťme se k inženýrovi, který inspiroval tento blog, a jeho poznámce, kterou „vysíláme do podniku“.
Když lidé říkají „ďábel v detailu“, mají na mysli, že malé věci v plánech a schématech, které jsou často přehlíženy, mohou v budoucnu způsobit vážné problémy.
Jeho komentář ignoroval kritický příspěvek udělaný do architektury internetu věcí okrajovým zařízením umístěným na každé vzdálené věci. Na rozdíl od tradičních M2M zařízení jako jsou RTU, PLC nebo jednoduché routery, poskytují okrajová (Edge) zařízení internetu věcí funkce pro zpracování dat ještě před jejich předáním.
Okrajová zařízení internetu věcí poskytují nejen fyzické síťové rozhraní pro zařízení nižšího řádu a čidla, ale poskytují nezbytný překlad, stejně jako oddělení dat získaných z těchto systémů a informací zasílaných do podniku:
- Filtrují data s malou nebo žádnou hodnotou. (Příklad: Teplota v místnosti je stejná, jaká byla před 10 sekundami – opravdu chci předat tyto informace podnikového systému?)
- Shromažďují tato data do souhrnných údajů. (Příklad: Minimální, střední a maximální hodnoty teploty v místnosti každé hodiny.)
- Poskytují detekcí události. (Příklad: Teplota přesahuje práh, nebo má nečekaně rychlou rychlost změny. Významná data jako tato mohou být upřednostněna a okamžitě odeslána.)
- Poskytuje obohacená data, zasazuje informace do kontextu něčeho, co je samo o sobě definované a sémanticky vyhledatelné. (Spíše než posílat, že „PLC31 registr 40072 má hodnotu 2078“ by se mělo poslat něco jako „B+B Galway / Timova kancelář, datum: 01.12.2015, čas: 10:40, teplota: 20 °C)
- Zajišťují správu komunikace a zabezpečení kolem datových transakcí.
- Umožňují uživateli obchodní logiku, která má být zakotvena v okrajových zařízeních k poskytování vysoce citlivé lokální inteligence.
Je velmi jednoduché hovořit o internetu věcí, když chybí ďábel v detailu. „My posíláme data do podniku“ je toho zcela jasným zřejmým příkladem. Pokud opravdu chcete znát rozdíl mezi M2M a internetem věcí, zvažte frázi „nevím, co nevím“. M2M systémy historicky ignorují neznámé, zatímco architektura internetu věcí ho objímá.
 Tim Taberner
Tim Taberner
Diplomovaný inženýr s rozsáhlými zkušenostmi v oblasti prodeje a řízení prodeje, řízení projektů, inženýrského vedení, hardwarového a softwarového inženýrství. Má významné zkušenosti v řešeních Machine to machine (M2M), internetu věcí, integrovaného computingu a systémů SCADA. Tim Taberner je častým řečníkem a široce publikovaným autorem na témata internetu věcí. Dříve zastával inženýrské, obchodní a marketingové pozice ve společnostech Transmitton, Arcom Control Systems nebo Eurotech. V současnosti pracuje jako Technický obchodní ředitel společnosti B+B SmartWorx.